Introduction
How should our microservices communicate with each other? As always, with microservices, there are a lot of choices available to us, including both synchronous and asynchronous communication patterns. We’ll explore several approaches to reliable communication between microservices.
Before we discuss this further, I would like to let you know I will use the same example from my previous article. If you want to get familiar with the example application, please read my article about Architecting Microservices.
We’ll start by looking at the big picture of communication between microservices. Should any microservice be allowed to communicate with any other? And what about client-facing applications such as websites and mobile applications? Can they call whatever microservice they want to? We’ll talk about how API gateways can be used to decouple front-end applications from back-end microservices.
We’ll see that microservices can use either synchronous or asynchronous communication styles. And in fact, many microservice architectures use a combination of both approaches.
We’ll look at RESTful APIs over HTTP, one of the most popular patterns for exposing microservice APIs. And we’ll see how message brokers support asynchronous messaging patterns and why that’s beneficial. For both synchronous and asynchronous communication styles, we’ll also talk about some of the patterns that support resilient communications to ensure that even when things temporarily go wrong, your system can cope with the problem and recover from it.
Finally, we’ll look at the challenge of service discovery. How can microservices know where to find each other? We’ll see how the service registry pattern can help us out here.
Microservice Communication Patterns
Are there any rules that govern which microservices should be allowed to talk to each other? For example, if I’ve got a few microservices, is it okay for them all to just call each other whenever it’s necessary? And if I’ve got a front-end application, like a website or a mobile application, should that also be allowed to call directly to any of the microservices it wants to?
Well, once again, microservices don’t specify any hard or fast rules here, but there are some difficulties with allowing a complete free-for-all situation like this. You can end up creating a mess of tangled dependencies between services that can result in cascading failures where one microservice failing causes the others to fail as well, and you can also end up with poor performance if making a call to one microservice ends up requiring multiple hops to call additional microservices. And if that’s what’s happening in your architecture, that might actually suggest that you’ve got some service boundaries in the wrong place. A better approach is to minimize calls between microservices.
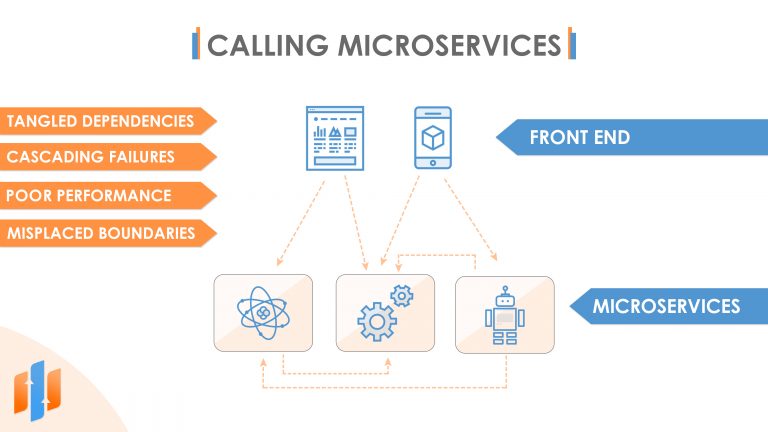
Instead, your microservices could publish messages to a shared event bus and also subscribe to messages on that bus. This promotes asynchronous communication between microservices, and we’ll be discussing the benefits of that later in this article.
When we’re dealing with front-end applications, particularly mobile applications or single-page applications where calls are coming into our microservices directly from a client-side application, we might prefer to avoid the client application needing to know how to connect to all our different microservices. Instead, a pattern can be used called an API gateway where all the calls from the front-end client application go through the gateway and are routed through to the correct microservice. This offers several benefits. It means we can provide implementation authentication at the API gateway level.
Generally, it makes security easier to reason about if all the external traffic enters the system at a single point. This approach also decouples the client application from the specifics of our back-end APIS giving us freedom to be more flexible with changes to our microservices while maintaining a consistent public-facing API. And this is especially important if third parties are creating the client applications for our APIs, meaning that we aren’t in control of their upgrade schedules.
A closely related pattern called Back-end for Front-end (BFF) builds on this idea. You can create an API gateway for each of your front-end applications, which might turn one incoming HTTP request into two back-end calls whose responses are aggregated or transformed into just the correct format to meet the needs of the front-end application.

Let’s see what approach the eShopOnContainers sample app takes. First of all, we can see that they’ve embraced the concept of back-ends for front-ends, or API gateways, and both the mobile application and the two websites communicate through the API gateways.
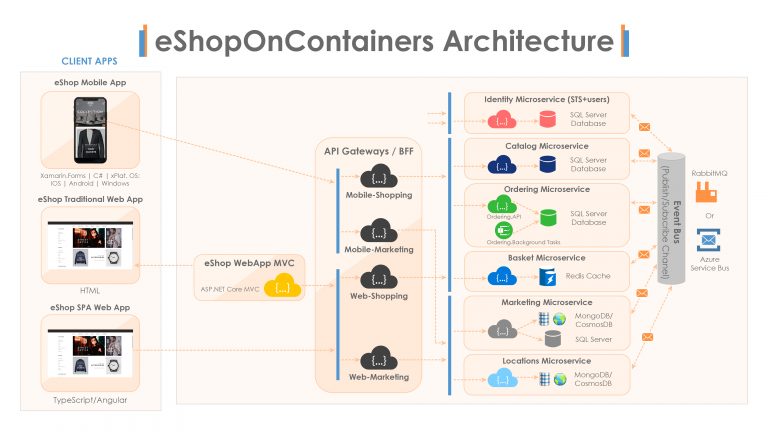
We can see that the microservices don’t call each other but are raising integration events to an event bus. This event bus is implemented either as RabbitMQ for when we’re running locally or Azure Service Bus for when we’re running in the cloud. And then, these messages are subscribed to by the other microservices and handled asynchronously. So this architecture is a good illustration of the fact that you can combine a few different approaches to communication patterns within the same system, using each one where appropriate.
So let’s dive a little bit deeper now into our options for both synchronous and asynchronous communications between microservices.
Synchronous Communication
By synchronous communications, we mean making a direct call to a microservice and waiting for it to respond to us.
A good example of when we need to do this is when the front-end is making a query. Say, for example, in the eShopForContainers web page, we want to show the top 10 most popular products available. To implement this, we’d make a request through the API gateway and into the Catalog microservice, and then that microservice fetches data from its database which is a SQL database in eShopOnContainers and returns it all the way back to the web page.

Because this is a synchronous communication, it’s important that this operation is optimized to complete as quickly as possible. We don’t want customers to be put off shopping with us by experiencing slow load times on our home page. And although there are many communication mechanisms available for calling microservices, HTTP is by far the most popular mechanism, and that’s because it’s an industry standard available in all mainstream programming languages including JavaScript, meaning that any web page or mobile application can easily call our microservices.
In addition, we can take advantage of some of the other characteristics of HTTP such as standardized approaches to reporting errors and the ability to cache responses or use proxies. The payload of a HTTP request in response to our microservices is typically going to be in JSON, although other options are available including XML.
One of the advantages of JSON is its wide support across the vast majority of programming languages, but also that it’s the native format that JavaScript likes to work with, so it’s really great when you’re calling your microservices from web pages.
Another pattern very often associated with microservice architectures is to implement your API as a set of RESTful resources. The RESTful approach to API design encourages you to represent the information that your service works with as resources. In eShopOnContainers, a resource might be a CatalogItem or an Order. Each of those resources is then manipulated using the standard HTTP verbs such as GET to retrieve a resource, POST to create a new resource, or PUT to update a resource. RESTful API design also encourages making good use of HTTP features such as meaningful response codes and using media types to specify how our resources should be represented.
Asynchronous Communication
Sometimes we might want to ask a microservice to do something that we don’t need to wait for. A good example in the eShopOnContainers website would be the process of submitting an order.
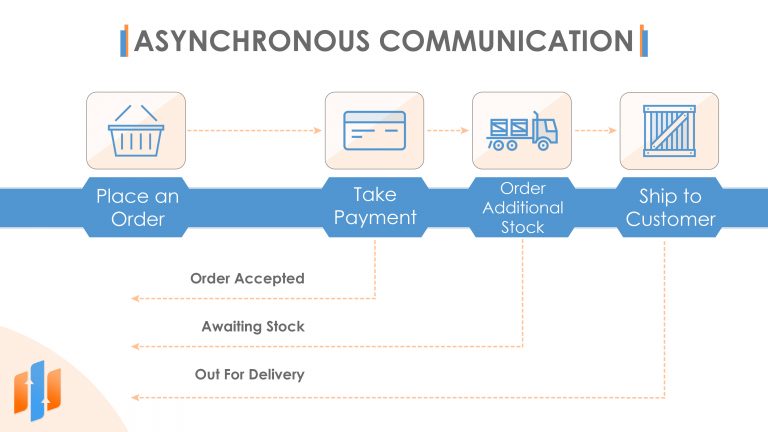
When we submit an order, there might be all kinds of tasks that need to be done by the back-end systems including taking payments from a payment provider, maybe ordering additional stock from a supplier, and then initiating the shipping process from the warehouse. And this process might take a few days to complete, and so we can’t expect the user of the website to wait all that time to get an order confirmation. They just need to know that their order has been accepted and they can come back later to check its progress. We might even send them email updates to keep them updated on their order status and let them know once it’s out for delivery.
We can achieve this by making use of asynchronous communication patterns. It is possible to implement asynchronous communication patterns over HTTP. For example, when a customer submits a new order, our Ordering microservice could return a 202 Accepted HTTP response code rather than a regular HTTP 200 OK response code. 202 means that you’ve accepted a request to do some work but you haven’t carried it out yet. And in the response body, you often send an ID of some sort so that the client can then pull for the status of that work to find out if it’s completed. In our example, that ID might just be the order number. You might also want to combine this technique with the use of webhooks where the microservice itself reports back when it’s completed the task. In this model, when a client calls your microservice, they can register a callback URL on which they’d like to receive any notifications.

But another very common pattern for asynchronous communications is for microservices to publish messages to an event bus.
Rather than directly calling the other microservices, they simply create a message and send it to a message broker, which serves as an intermediary. Other microservices then subscribe to those messages. And this pattern has a number of advantages.
First of all, it completely decouples the microservices from each other. So instead of one service directly calling the next service, instead it simply talks to the message broker. This means that if the second service is temporarily unavailable, then the first service is still able to function, and the second service can just process any queued-up messages once it’s online again. This approach is also very beneficial for supporting more advanced scaling patterns.

If the number of unprocessed messages for a microservice is building up, you can scale that microservice out to multiple instances to help work through the backlog of messages quickly. And many serverless hosting platforms do this automatically for you. But with containerized solutions, it’s also possible to achieve the same thing by configuring some automatic scaling roles for the cluster of virtual machines that your containers are running on.
There are several different types of messages that you can use. Two of the most important types of messages are commands and events.
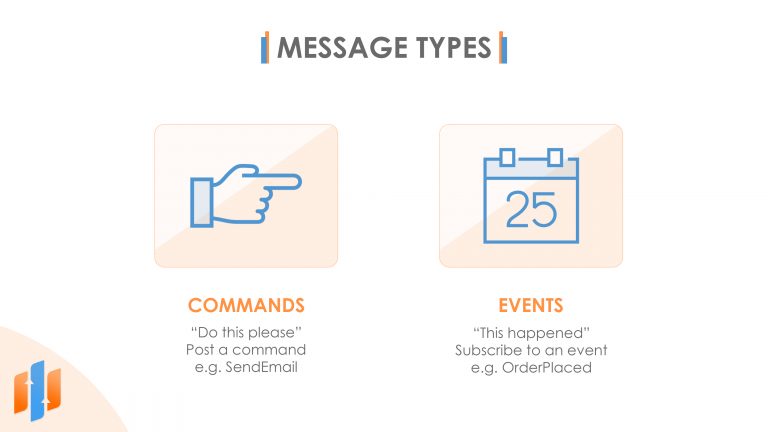
A command message is a request for a particular action to be performed. You can think of a command message as saying, Do this please. Imagine you have a microservice that sends out emails. That doesn’t necessarily need to work synchronously, so it’s a good fit for asynchronous patterns. We could post a command message that specified the details of the email that should be sent, and the email microservice could pick that up and send the message. Maybe the email microservice could get a bit behind if we posted large numbers of these command messages to its queue but it would eventually catch up.
The other type of message is an event. An event message is simply a way of announcing that something has happened. Events are in the past tense and are not directed at any one microservice in particular. When you publish events, you’re allowing any other microservices in your system that are interested to subscribe to that event and perform their own custom actions when it occurs.
For example, if there was an OrderPlaced event in an e-commerce system like eShopOnContainers, then several actions might need to occur as a result of that event. For example, charging your credit card, sending a confirmation email, or checking on stock levels. And so each microservice that needs to perform an action when an order is placed will be triggered by that single event being posted to the event bus.
Resilient Communication Patterns
We can’t assume in a distributed system that all the microservices will be up and running the whole time. We can’t even assume that the network is going to be reliable. So we must expect from time to time that communication from service to service will fail due to transient issues. And it’s very important that we handle these failures well as they can result in cascading failures that are very difficult to recover from.
There are several techniques and patterns that we can apply to increase the resilience of our service-to-service communication. I’ll just mention a few of them. If you’re making any kind of network call, such as a regular HTTP request to another service or maybe making a query to a database, then it’s a great idea to build in retries with back-off. This means that if your first attempt fails, then you just wait a few seconds and try again, and if that fails, then you wait a bit longer and make another attempt. And this simple technique can often be all that’s necessary to handle various transient service outtakes.

And you might find that your programming framework has built-in support for this functionality. For example, in .NET, a great library called Polly makes this very easy to implement. However, suppose too many retries are attempted. In that case, you can end up making the situation worse, and potentially you effectively issue a denial of service attack on your downstream services because you’re calling them so frequently.
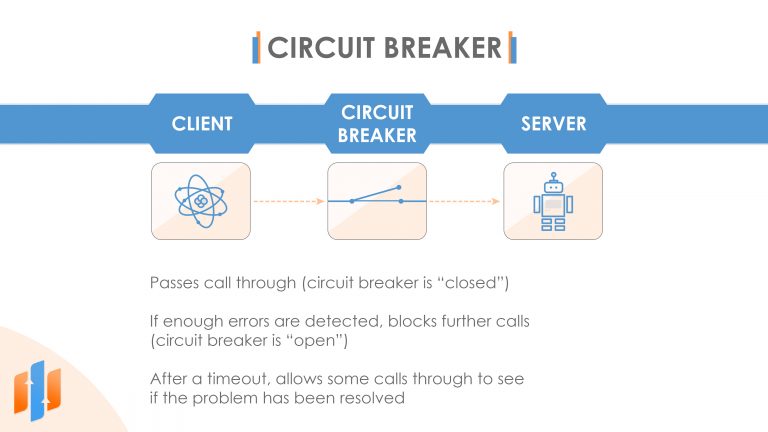
So another pattern that can help us with this is called a circuit breaker. A circuit breaker sits in between the client and the server, and initially it allows all calls through. And we call this being in the closed state. However, if it detects any errors, maybe the server is returning error codes or it isn’t responding at all, then the circuit breaker opens, which means now whenever the client makes a call, it’s going to fail fast rather than passing on that request to the server. But after a configured timeout has elapsed, the circuit breaker allows a few calls through again to see if the downstream service has recovered. If so, then the circuit break closes, and it allows all calls through again. If the downstream service hasn’t recovered, then it remains in the open state a bit longer, again quickly rejecting any incoming requests. And this is a very simple but powerful technique. And, again, many programming frameworks will have ready-made implementations of a circuit breaker that you can take advantage of.
Caching can also be a valuable part of a resilient strategy. If you cache the data that you receive from a downstream service, then if that service is unavailable for a short period, you might be able to fall back to the data in your cache. Of course, that assumes that you have thought about the implications of using stale data. One of the reasons message brokers are so popular in microservice architectures is that they have inherent support for resilience. We can post messages to the message broker, and it doesn’t matter if our downstream services are not currently online. When they start up again, they can catch up on the backlog of messages that are waiting for them. Message brokers also often support the ability to retry sending a message. If a message handler fails for any reason, the message can be returned to the message broker to be redelivered later, and this effectively means that you get a certain number of retries for free simply by using messaging patterns. Of course, you don’t want to get stuck in an infinite loop attempting to process the same message again and again. So usually after a certain number of retries, the message broker will consider this message to be poisoned and put it into a dead-letter queue.
Now there are some challenges associated with messaging that you do need to consider. One is it’s very hard to guarantee that messages will always be received in order. So you need to take care that your message handlers will do the right thing even if they receive messages out of order. It’s also possible to receive a message more than once. One example of when this can happen is when you receive a message for the first time, maybe you only got part way through handling it and something went wrong, and so the message got returned to the queue. And now later, you receive that same message again as a retry. And this scenario is why it’s really important to ensure that your message handlers are idempotent. A message handler is idempotent if calling it twice with the same message has essentially the same effect as calling it once.

A good example in our e-commerce sample application would be handling an order. We only want to charge your credit card once, and we only want to ship your order once. So if the order received message gets processed twice for whatever reason, we need to make sure that we’ve got good checks in place in our code to protect us from charging you twice or shipping your order twice.
Service Discovery
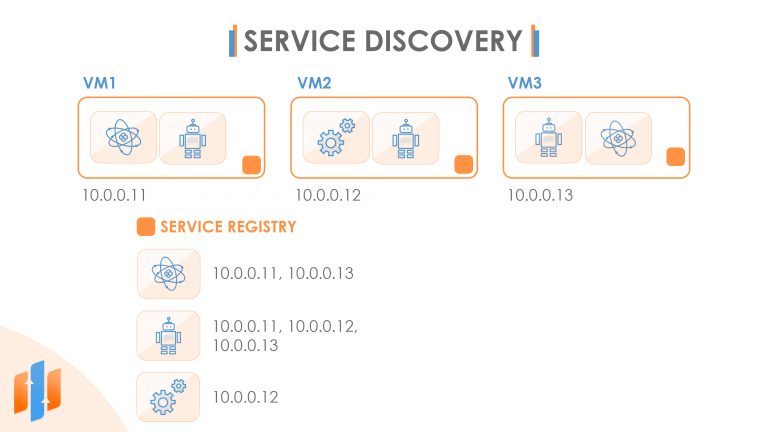
For our microservices to be able to communicate with each other, each microservice needs to have an address. But how can we find out what address all the other microservices are located at? Let’s imagine we’ve got three virtual machines and we’ve got various microservices running on each machine. Maybe we’ve even got multiple instances of some of the microservices running on different machines in our cluster of virtual machines. Now we don’t want to have to hardcode IP addresses in as that gives us poor flexibility to dynamically move our microservices between virtual machines in the cluster, which is necessary in the cloud as machines do need to be taken down from time to time for servicing purposes.
Now there are a few ways that we can solve this problem. And one is to make use of what’s called a service registry. This is a central service that knows where all the other microservices are located. Sometimes this works by each service reporting its location to the service registry when it starts up and keeping in touch to allow the service registry to know that it’s still available at that address. That means that whenever you want to communicate with another microservice, you can ask the service registry to tell you where that microservice can be found. And the service registry itself is typically distributed across all the machines in your cluster, which makes it simple for you to be able to contact the service registry.
But you don’t necessarily need to build your own service registry. A number of microservice hosting platforms solve this tricky problem for us by means of DNS.
For example, if you’re using a PaaS platform to host your microservices, then often each microservice you deploy will automatically be allocated a DNS name that points to a load balancer sitting in front of the actual instances of your microservice. And that means you can just use the DNS name to communicate with your microservice and not have to worry about the actual IP addresses of the individual virtual machines that are running the service and might change over time. Or if you’re using a container orchestration platform, like Kubernetes, then you can simply refer to the other services just by their service name. Kubernetes has got its own built-in DNS, and that means you don’t need to know the IP addresses of each container. You just need to know the name of the service you want to talk to, and it takes care of routing traffic to the container that’s running your service and load balancing if necessary. So the challenge of service discovery tends to be much easier if you’re planning to host your microservices application on a modern microservice-friendly platform.
Module Summary
In this article, we’ve talked about several different ways that microservices can communicate with each other. There are no hard and fast rules about what you have to use, but two of the most common mechanisms are implementing RESTful APIs, which allow your clients to make synchronous HTTP calls to your microservices, and publishing messages to an event bus, which allows asynchronous communication patterns. And these two approaches are not mutually exclusive, and it’s quite acceptable to use them both in the same system.
We also talked about the API gateway or back-end for front-end pattern where we put an intermediate proxy between our front-end applications and our back-end services.
We also looked at some techniques that support resilient communication patterns, including the use of retries, circuit breakers, and caching with synchronous communication. And for asynchronous communication, we saw how we can take advantage of message retries and that we need to make sure our message handlers are idempotent.
Finally, we talked about that service discovery can be implemented using a service registry and that many modern PaaS microservice hosting platforms and container orchestrators like Kubernetes can solve this problem automatically for us, making our lives much simpler.
Looking for an IT Consultant?
Every IT consultancy challenge is unique. Whether you're looking for a short-term or long-term solution, you can trust SonicSoft to provide options tailored to your needs.