Introduction
Whether you’re planning to migrate an existing application to microservices or adopt a microservices architecture from the start of a brand new project, you need to make some significant architectural decisions upfront. In this article, we’ll discuss some fundamental architectural principles for defining a microservice and its components. We’ll begin by discussing that you don’t have to start with microservices, and it’s possible to evolve an existing application towards them. We’ll look in a bit more detail at some of the critical definitions of a microservice, including the fact that a microservice should be autonomous, which means it owns its data. And a microservice should be independently deployable, which means it needs to have a clearly defined and backwards-compatible public interface. Finally, we’ll discuss the tricky challenge of how we can identify appropriate service boundaries for our microservices. We’ll look at some guidelines for breaking applications into microservices, including the idea of identifying bounded contexts.
Introducing the Demo Application
I don’t want microservice articles to be purely theoretical, so we’ll be referring to a simple microservices application as we go through this article, illustrating the principles we’re learning about. And, rather than spending a few months creating my own microservices application, I’ve decided to use a pre-existing reference microservices implementation called eShopOnContainers, which is open source and available here on GitHub. And there are a few reasons why I picked this example to use in this article. First of all, e-commerce is a well‑known problem domain. We’ve all used a shopping website, so it should be reasonably straightforward for you to understand the responsibilities of the various microservices such as the basket, catalogue, and ordering services. But it’s also a non‑trivial example.
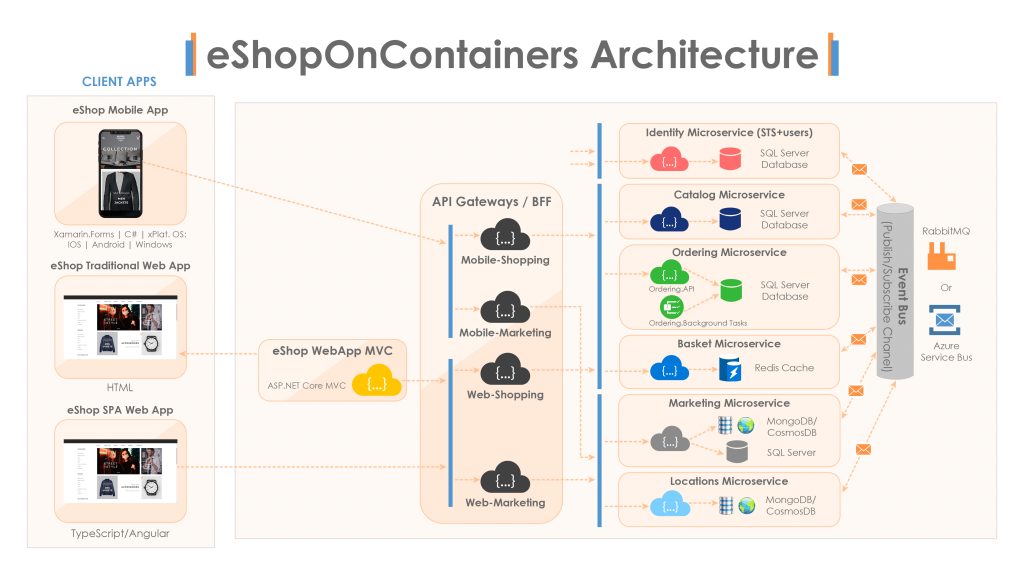
As you can see from below system architecture diagram, there are three client applications, two websites and a mobile app, and six microservices, using a few different database technologies and communicating via an event bus. And this sample also makes use of a pattern known as an API Gateway, or Backend for Frontend. It’s also being actively maintained, and it’s regularly updated with newer technologies and practices.
we’re going to start looking at how we can architect a microservices solution
Evolving Towards Microservices
You may already have an existing application with a monolithic architecture. Or maybe you’ve even got what we described in the previous module as a distributed monolith, where several services are tightly coupled and not independently deployable.
The good news is that it’s perfectly possible to evolve towards a microservices architecture. You can augment a monolith with microservices where you create a new microservice every time you add a new capability. And you can decompose a monolith into microservices where you identify existing capabilities that should be extracted into their independent microservices.
Some argue that you should avoid starting a new project with a microservices architecture. The benefits of microservices are not typically seen in small, new projects. And it can be tough to get service boundaries, right. So it might be better to allow a system to grow until it becomes apparent what appropriate segregation of responsibilities into microservices would be.
Now, of course, when you are using microservices, at some point, you need to identify a microservice’s responsibilities and define its public interface. So let’s look next at some of the critical principles of microservices that help us make these sorts of decisions.
Now, of course, when you are using microservices, at some point, you need to identify a microservice’s responsibilities and define its public interface. So let’s look next at some of the critical principles of microservices that help us make these sorts of decisions.
Microservices Own Their Data
As we discuss earlier, microservices are autonomous and independently deployable. And a crucial part of achieving these goals is ensuring that a microservice owns its data. In other words, we’re not allowed to have this situation where multiple microservices read or write from the same data store.
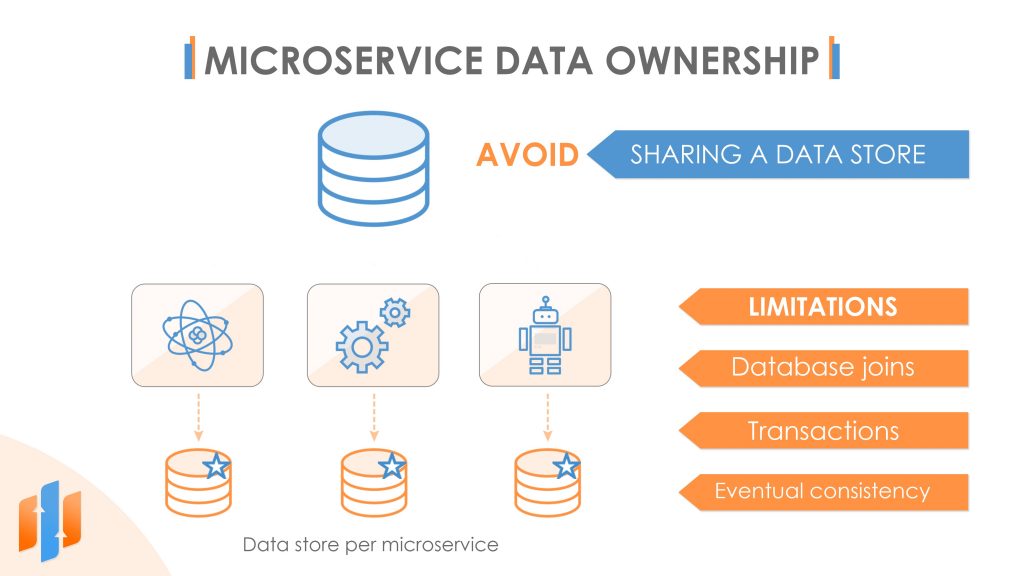
Instead, each microservice should have its data stored, and any other microservice wishing to access it must do so via the public API of the microservice that owns it. Now there are some apparent trade-offs here. Splitting our data out means, we can no longer perform database joins across the data held by two different microservices. Instead, we will have to make separate calls to each database. And we can no longer update two tables owned by other microservices within a single database transaction. Instead, we’d either have to use distributed transactions, which are very complex to implement, or, more commonly, design our system to work in what’s called an eventually consistent manner where we may have to wait a while for the overall state of the data to be entirely compatible. What this means in practice is that when a single business operation requires updates to more than one data store, there will be a short window of time when the change has been made in one data store but not the others. And so, you need to develop your application to cope with this temporary inconsistency.
Now there are ways to mitigate these issues. If we define our service boundaries well, we can minimise the need to aggregate data from multiple microservices to perform a single operation. Another approach is that one microservice might hold its cache of a subset of the data owned by another microservice.
An example might be that we could maintain our cached copies of this data rather than constantly talking to a user profile service to get a user’s name or email address. And this approach dramatically improves performance because it removes the need for many chatty network communication and improves availability since our microservice can now do its job even when the user profile service is unavailable.
It’s important When you consider how to break your application into microservices, you must identify natural seams in the database schema. This will help you avoid the performance penalties of involving multiple microservices in a single business operation.
EShopOnContainers Architecture
To illustrate how microservices should own their data, let’s look at the eShopOnContainers sample application. We can see that the Catalog service uses a SQL Server database, and the Ordering service also uses SQL Server, but it’s a different database. Neither of these services can see or access each other’s data directly in the database. The Basket service uses a Redis cache, a more appropriate choice for short-lived data. We can also see that document databases such as Cosmos DB or Mongo have been chosen by some of the other microservices in this application. And so, this architecture illustrates two key microservice characteristics. First, each microservice in eShopOnContainers owns its data. And second, each microservice is free to use the most appropriate database technology for the type of data it needs to store. This breakdown of microservices also highlights a way to approach one of the difficulties we just discussed.
The Ordering Microservice has got a concept of an OrderItem, which represents a single item in your order. The OrderItem entity contains a ProductId, a ProductName, and a UnitPrice. Now, hang on a minute. Shouldn’t the Catalog microservice be responsible for owning product names and prices? And yes, the Catalog microservice has an entity called CatalogItem, which has an Id, a term, and a price. So when you order something, the Ordering microservice records the product’s ID and takes a copy of its name and price. And so we’ve got the same information, sometimes referred to as denormalisation in databases. This means that if we were to update a product’s name or price in the Catalog microservice, then the information in the OrderItem would become stale. So wouldn’t it be better then if the Ordering microservice didn’t store the product name and price and instead asked the Catalog microservice whenever needed? actually, maybe not.
For one thing, that wouldn’t perform exceptionally well as now we’ve introduced another network call. But another consideration is that it might be a good thing for your order to include the product’s name and price as it was when you placed the order. In other words, the Ordering microservice doesn’t care about the product’s current price and name. What it cares about is what they were when you placed the order. And so, in fact, this isn’t duplicate information. These pieces of data have different meanings within the context of each microservice. And so, duplication of data between microservices and the inability to do a direct database join between the data owned by two microservices is not necessarily the problem that it might first appear to be.

Components of a Microservice
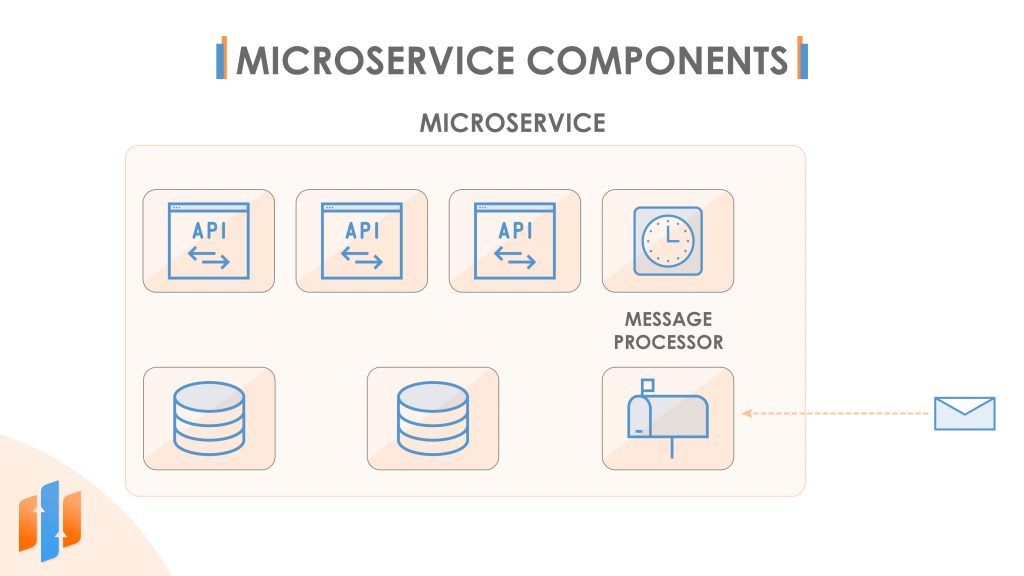
The fact that a microservice owns its data leads us to realise that a microservice is not necessarily a single process running on a single host. Often at a minimum, there’s your code, perhaps implemented as a web API and the database. So that’s at least two processes, and, often, they’re not running on the same host.
If we scale-out, now we’ve got multiple replicas of our code running on different hosts and sharing access to a single database. And if we were to configure our database for replication or sharding, that too might be running on more than one host. A microservice might also have a cron job working on a schedule to perform data maintenance. And maybe it has another process: listening for messages on a cue that trigger various other data updates. So, there may be several different hosts and processes involved in a microservice. But conceptually, they form a single microservice, and only these components are allowed to access the shared data.
We can see this illustrated again in the eShopOnContainers sample application. If we look at the Ordering service, we can see that it not only contains a web API called Ordering.API, but there’s a separate process to implement background tasks called Ordering.BackgroundTasks, which is used to provide a grace period feature. And this is a perfectly acceptable design for a microservice. You’re not forced to have all of the microservice code running in a single process. The important thing is that conceptually, a microservice has a clearly defined boundary with a public interface, and its data can only be accessed through that public interface. Let’s talk about microservice interfaces next.
Microservices should have a clearly defined public interface
Identifying Microservice Boundaries
How can we work out the best way to break our system into microservices? This is a difficult task and easy to get wrong. Drawing service boundaries in the wrong place can result in poor system performance and be hard to change once those services run in production.
So it’s worth dedicating some time to consider your options in this area. In some ways, your task is easier if you’re starting from an existing monolithic application. Very often, there will already be some modularisation, and some of those modules might be suitable candidates for converting into microservices, especially if they’re loosely coupled with the rest of the system through a clear interface.
Since microservices own their own data, looking for seams in the database is often a good idea. Are there certain groups of tables that conceptually belong together? If so, identify all the places in the code that will read and write from those tables and see whether they can be extracted to form a microservice.
A helpful guideline is that microservices should be organised around business capabilities. You may be familiar with the concept of domain-driven design. This encourages us to identify bounded contexts within our applications. This is a way of breaking up the domain model for a large system, with each bounded context having its own ubiquitous language and relating to one specific business capability or subdomain. And often, these will map onto the organisational structure of the business. You then define some models that apply within your bounded context, and this means that different microservices will use different models and even might use different terminology for the same thing.
We saw that earlier where the products that eShopOnContainers sells are called OrderItems by the Ordering microservice and CatalogItems by the Catalog microservice. Although they both relate to a product sold by the shop, they’re being used in different contexts. And so they have different properties, and they’re free to use different names for the same piece of information.
Now it can be daunting to come up with good service boundaries. So a great approach to testing your ideas is to sketch them on a whiteboard, run through some real-world use cases for your application, and see which services would be involved. That can help you identify potential problems if too many services are required to collaborate together to achieve a single business capability.
You can run into some pitfalls when choosing your microservice boundaries. One is if you simply take all the nouns in your domain and turn them into services. This often ends up with you creating what is sometimes called anemic CRUD services, which are little more than wrappers around tables in a database with methods to add and update entities while the logic related to those entities remains distributed across the rest of the system. Another sign that your boundary is not quite right is when you have circular dependencies between your microservices or clusters of microservices that all need to communicate frequently with one another.
Microservices can be upgraded without their clients needing to upgrade
EShopOnContainers Service Boundaries
Let’s take a look at the choices made by the architects of the eShopOnContainers sample application to see some of these principles in action.
There’s a Catalog microservice responsible for storing details of the products available in the shop. Another microservice tracks what the customers have got in their basket. And then there’s an Ordering microservice, which is responsible for handling the orders that we’ve placed in the shop. These three services relate to three distinct parts of the online shopping experience.
The Catalog microservice supports browsing for products. The Basket microservice deals with preparing for a purchase. And the Ordering microservice deals with the business process of handling an order. And this separation of responsibilities makes a lot of sense. For one thing, it helps with resilience as customers will be able to browse for products to buy and put them in their basket, even if the Ordering microservice is temporarily unavailable. It also makes sense from a scalability perspective. Each of these microservices deals with very different volumes of data and access patterns.
For example, the catalogue is potentially very large and needs to support flexible queries as customers are searching for items that they want to buy based on various criteria. That means it makes sense for the Catalog microservice to store its data in a database that supports rich querying. And we can see here that it’s using SQL Server, which makes a lot of sense for this kind of use case, whereas the Basket service deals with very short-lived data, so it may not even need to be written to a database. And in fact, eShopOnContainers actually uses Redis, a memory cache to store basket data. The Ordering microservice is mostly writing new data to the database whenever a customer places an order. It’s got very strict requirements for reliability. We certainly don’t want to lose any orders. And it’s also handling extremely sensitive data such as people’s addresses and payment information. So its security requirements are very different from those of the Catalog service, whose data is freely visible to everyone. There’s another microservice here that handles identity, and this helps deal with authentication concerns. The Marketing microservice relates to a completely different part of the business from the Basket and Ordering microservices. This microservice sends out email campaigns, which requires knowing where in the world our potential customers are located. And we can see here that there’s a Location microservice that handles this responsibility. Obviously, the architects felt that this was a sufficiently complex component to warrant its own microservice. And, of course, this isn’t the only way that you could break this domain down into microservices. But on the whole, I think that some good choices have been made here. And in fact, this might be a good time for you to take some time to think about the project that you’re working on. How would you break it up into microservices? What responsibility would you give to each one? And what data would each of those microservices own?
Summary
In this article, we’ve looked at some of the key considerations involved in architecting a microservices application. You can evolve an existing system towards microservices by augmenting it with new microservices or by extracting existing functionality into microservices. We saw that microservices should own their own data, and they may consist of more than one process. Microservices need to be independently deployable. This requires taking care not to make breaking changes to the API or doing anything else that forces the clients of a microservice to be upgraded simultaneously with the service. The concept of bounded contexts from domain-driven design should be applied to identify suitable boundaries for a microservice. And getting those boundaries right is a critical factor in being successful with microservices.
Evolving towards microservices Microservices own their own data Microservices may consist of multiple processes Microservices should be independently deployable Avoid breaking changes Identify “bounded contexts” for microservice boundaries Getting boundaries right is important.
Looking for an IT Consultant?
Every IT consultancy challenge is unique. Whether you're looking for a short-term or long-term solution, you can trust SonicSoft to provide options tailored to your needs.